
Our approach
We work with you to identify the best way to ask survey questions, create strategies for collecting feedback, and sift through data to make impactful decisions. We also educate on the principles of telling stories with data and linking employee feedback data to key business metrics.
Evidence-backed
We combine peer-reviewed literature with field experience and customer insights to craft recommendations that acknowledge the complexity of contemporary workplaces. We know that even the slightest ambiguity can derail survey results, so a rigorous approach is vital.
Always innovating
We make hypotheses, test them, learn, and iterate to bring you the best methodologies for collecting data you can trust.
Positive growth mindset
We believe in approaches that will engage and develop your people to improve business outcomes.
Thought partnership
Our customers enjoy unrivaled support, education, and upskilling from some of the world’s brightest minds in people science.

“We have empathy and understanding about the problems a customer and their leadership is facing, beyond what one can gather from a theoretical or data-driven perspective alone.”
Jason McPherson
Culture Amp Founding Scientist
A window into regrettable attrition
If you have low scores on your Engagement survey, it’s natural to question who the unfavorable results are coming from. Our research indicates they might be from the very employees you most want to keep!
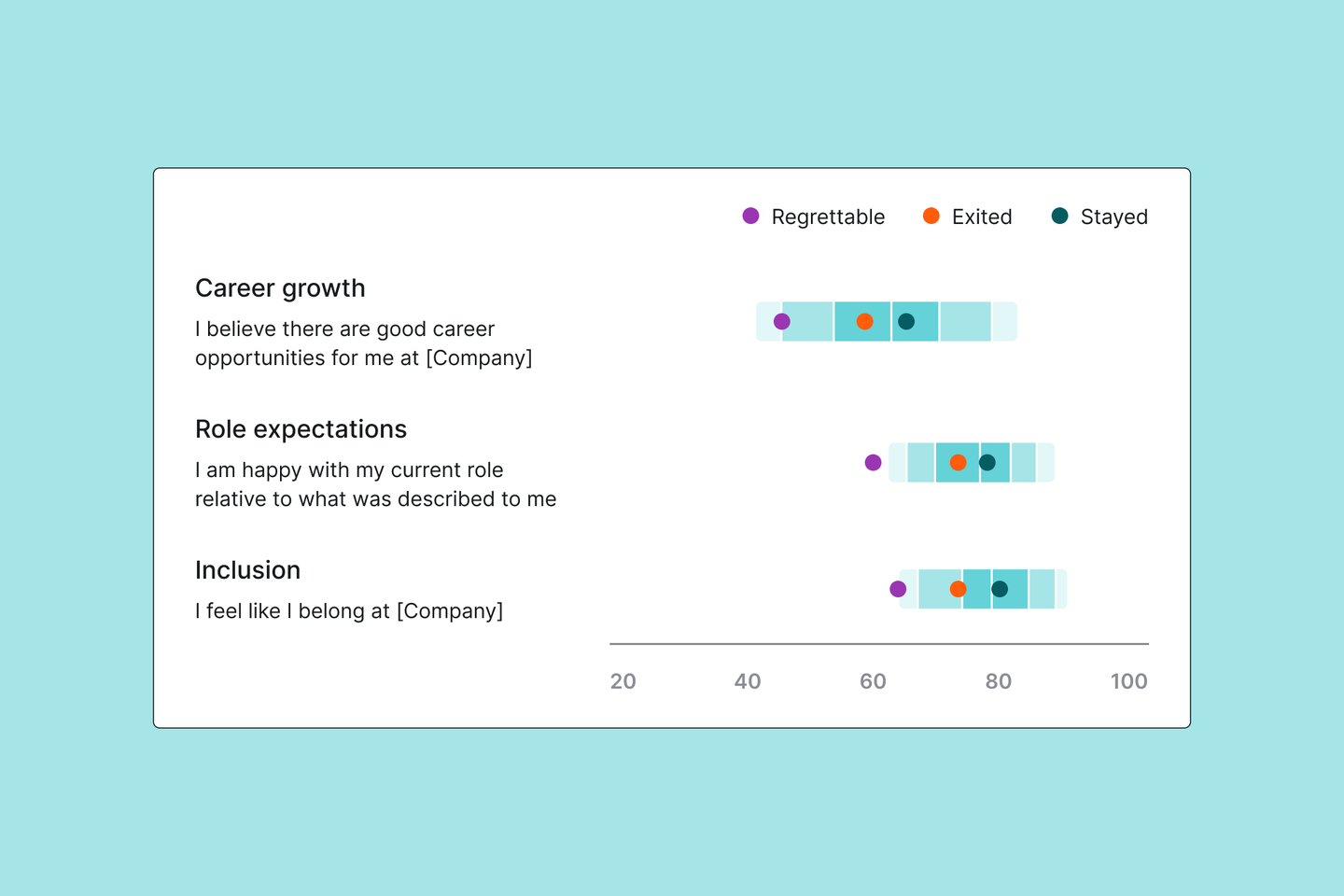
Fig 1: A window into regrettable attrition
Our nimble, in-house team listens to your company’s goals
Culture Amp helps you apply the latest learnings from industrial/organizational psychology, organizational development, and data science to improve your business.
Data you can use
We analyze millions of responses – worldwide, across industries – feeding insights from top-performing companies back into our platform to help you collect meaningful data and enact positive change.
Founded on people science
At Culture Amp, people science has been embedded into the platform from the start. Our in-house experts blend industrial/organizational psychology and data science with real business insights and user empathy to understand and meet the multifaceted needs of our customers.
A world-class team
With PhDs in everything from industrial/organizational psychology to machine learning, our expansive, interdisciplinary team has decades of industry experience, previously holding roles at Deloitte, Google, Mercer, Korn Ferry, and other leading organizations.
Diverse insights
Our people scientists specialize in behavioral psychology, occupational health, organizational development, diversity and inclusion, business analytics, change management, and more. This diversity gives our team breadth and strength, helping us forge new paths to get you the best results.
Leadership spotlight

Chloe Hamman, Director of Product People Science
Chloe, who holds a master’s in organizational psychology, is a director of People Science and heads Culture Lab, our in-house research institute. She has over 15 years of experience in organizational behavior and culture, people development, and workplace wellbeing from her work in consulting and leading employee engagement programs. Chloe and her Culture Lab teams bring together people science, data science, and machine learning to explore new ways to analyze and connect data. They combine the world’s best methodologies with the world’s best test environment to drive product innovation for our customers.

Kenneth Matos, Director of People Science
Kenneth shares his vast expertise with the Culture Amp community, leading our global team of people scientists in helping customers transform their employee experience via evidence-based techniques. Widely cited in peer-reviewed journals and major news outlets, his research covers issues of diversity and inclusion, employee wellbeing, leadership, and organizational culture. Prior to Culture Amp, Kenneth provided technical and strategic leadership on a wide range of workforce research and consulting projects. He holds both a master’s in industrial and labor relations and a PhD in industrial/organizational psychology.